模型层
介绍
在 MVC(NTV) 设计模式中, M 表示的��是对数据库的操作, 对于正常的 Python 操作 Mysql 我们使用的操作是使用类似 pymysql 这类第三方模块库, 来进行操作
conn = pymysql.connect(host='137.78.5.130', port=3306, user='root', passwd='123456', db='test')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("insert into host (hostname,port,ip) values('ubuntu','22','10.0.0.2');")
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
可以看到对于平时使用的操作是很麻烦的, 如果我们要操作一些数据表就需要写大量的 SQL 语句, 为此推出了 ORM(对象关系映射) 这个工具是使用一个中间工具将 Python 代码翻译成原生的SQL语句. ORM将一个Python的对象映射为数据库中的一张关系表。它将SQL封装起来,程序员不再需要关心数据库的具体操作,只需要专注于自己本身代码和业务逻辑的实现。大致操作可以如下所示
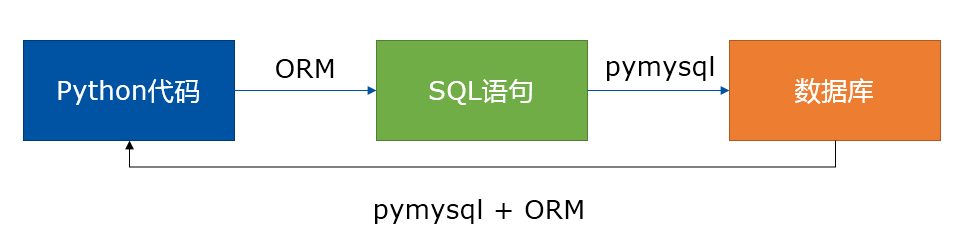
Django自带ORM系统,不需要额外安装别的ORM。当然,也可以安装并使用其它的ORM,比如SQLAlchemy,但是不建议这么做,因为Django系统庞大,集成完善,模型层与视图层、模板层结合得比较紧密,使用自带的ORM更方便更可靠,并且Django自带的ORM功能也非常强大,也不难学。
Django的ORM系统体现在框架内就是模型层。想要理解模型层的概念,关键在于理解用Python代码的方式来定义数据库表的做法!一个Python的类,就是一个模型,代表数据库中的一张数据表!Django奉行Python优先的原则,一切基于Python代码的交流,完全封装SQL内部细节。
模型和字段
模型可以理解为是一个使用 Python 表示的数据表字段和操作方法 基本原则如下所示:
- 每个模型在 Django 中存在的形式都是一个 Python 类
- 每个类都是
django.db.models.Model的子类 - 模型(类)的每个字段(属性)代表数据表的某一列
- Django自动为你生成访问数据库的API
下边是一个典型的 person 模型, 其中每个字段都是一个类属性, 每个属性表示数据表中的一个列
- 示例代码
- SQL 语句
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
CREATE TABLE myapp_person (
"id" serial NOT NULL PRIMARY KEY,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL
);
其中 Django 会帮助我们做一些自动化的操作:
- 表明
myapp_person是由 Django 自动生成的, 默认格式为项目名称_小写类名 - Django 可以自动创建自增主键
id, 也可以自行指定
之后编写了模型之后, 不要忘记将对于的 APP 注册到项目 settings.py 文件中, 至于原因请查看 python manage.py migrate 命令的作用是什么
模型的属性
对于不同的模型可以定义不同的属性, 来定义模型的具体操作, 其中最关键的是 Manager管理器。它是 Django 模型和数据库查询操作之间的API接口,用于从数据库当中获取数据实例。如果没有指定自定义的 Manager ,那么它默认名称是 objects,这是Django自动为我们提供和生成的。Manager 只能通过模型类来访问,不能通过模型实例来访问,也就是说,只能Person.objects,不可以jack.objects。
同样对于我们进行 CURD 操作, 还有一个隐藏的属性 _state , 该属性指向一个ModelState类实例,它持续跟踪着模型实例的生命周期。_state 有两个属性: adding 和 db:
- adding : 一个标识符,如果当前的模型实例还没有保存到数据库内,则为True,否则为False
- db : 一个字符串指向某个数据库,当前模型实例是从该数据库中读取出来的。
>>> from apps.polls.models import Person
>>> person = Person.objects.create(first_name="BUSHI", last_name="GEMENG");
>>> person._state.adding
True
>>> person._state.db
# None
在实际操作中如果存在不一样, 请关闭自动提交
模型方法
在模型中可以添加一些自定义方法, 来为 行级 数据操作提供一些功能, 比如下面这个示例
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
birth_date = models.DateField()
def bady_boomer_status(self):
"Returns the person's baby-boomer status."
import datetime
if self.birth_date < datetime.date(1945, 8, 1):
return "Pre-boomer"
elif self.birth_date < datetime.date(1965, 1, 1):
return "Baby boomer"
else:
return "Post-boomer"
@property
def full_name(self):
"Returns the person's full name."
return '%s %s' % (self.first_name, self.last_name)
bady_boomer_status()是我们自定义的一个模型方法, 可以被任何Person的实例调用,进行生日日期判断full_name被Python的属性装饰器转换成了一个类属性
具体操作示例如下所示:
>>> person = Person.objects.get(pk=2)
>>> person.bady_boomer_status() # 以执行函数的方式调用
'Post-boomer'
>>> person.full_name # 以属性的方式调用
'BUSHI GEMENG'
同样 Django 也提供了一些内置的模型方法:
__str__(): 这个其实是Python的魔法方法,用于返回实例对象的打印字符串get_absolute_url(): 这个方法是返回每个模型实例的相应的访问url__hash__(): Django在内部还为models.Model实现了__hash__()魔法方法,给模型实例提供唯一的哈希值。这个方法的核心是hash(obj.pk),通过模型主键的值,使用内置的hash方法生成哈希值。如果实例还未保存,没有主键值,显然会发生错误。哈希值一旦生成就不允许修改。
模型字段
对于 Django 不允许以下几种字段名称存在:
- 与Python关键字冲突。这会导致语法错误
- 字段名中不能有两个以上下划线在一起,因为两个下划线是Django的查询语法。
- 字段名不能以下划线结尾,原因同上。
Django内置了许多字段类型,它们都位于 django.db.models 中,例如models.CharField,它们的父类都是Field类。这些类型基本满足需求,如果还不够,你也可以自定义字段。(字段名采用驼峰命名法,初学者请一定要注意)
关系类型字段
在前面介绍 Django 中主要的数据类型字段, 但是对于 SQL 而言还有一些关系型的数据字段
- 多对一 (ForeignKey) : 变量名一般设置为关联的模型的小写单数
- 多对多 : 变量名一般设置为小写复数
多对一 (ForeignKey)
所谓多对一其实就是所为的外键, 在 Django 中对于外键的字段类的定义如下所示:
class ForeignKey(to, on_delete, **options)
其中需要两个参数: 一个是关联的目标模型是什么, 另一个是对应的行为是什么
下面我们使用 工厂-车 的关系来介绍一下 Foreignkey 的关系
- Model 在同一 py 文件中
- Model 不在同一 py 文件中
from django.db import models
class Manufacturer(models.Model):
name = models.CharField(max_length=20)
class Car(models.Model):
manufacturer = models.ForeignKey(Manufacturer, on_delete=models.CASCADE)
name = models.CharField(max_length=20)
price = models.CharField(max_length=20)
from django.db import models
class Car(models.Model):
manufacturer = models.ForeignKey(
'production.Manufacturer', # 关键在这里!!, 改为引号使用
on_delete=models.CASCADE)
name = models.CharField(max_length=20)
price = models.CharField(max_length=20)
还有一种特殊情况, 就是要创建一个递归的外键,也就是自己关联自己的的外键,使用下面的方法:
models.ForeignKey('self', on_delete=models.CASCADE)
核心在于‘self’这个引用。什么时候需要自己引用自己的外键呢?典型的例子就是评论系统!一条评论可以被很多人继续评论,如下所示:
class Comment(models.Model):
title = models.CharField(max_length=128)
text = models.TextField()
parent_comment = models.ForeignKey('self', on_delete=models.CASCADE)
# .....
注意上面的外键字段定义的是父评论,而不是子评论。为什么呢?因为外键要放在‘多’的一方!
在实际的数据库后台,Django会为每一个外键添加_id后缀,并以此创建数据表里的一列。在上面的工厂与车的例子中,Car模型对应的数据表中,会有一列叫做manufacturer_id
接下来我们对其中的各项参数进行一些介绍
- on_delete
- limit_choices_to
该参数不可以省略, 其用来限定在关联对象删除时, 对应的数据应该如何处置
- CASCADE : 模拟SQL语言中的ON DELETE CASCADE约束,将定义有外键的模型对象同时删除!
- PROTECT : 阻止上面的删除操作,但是弹出ProtectedError异常
- SET_NULL : 将外键字段设为null,只有当字段设置了null=True时,方可使用该值。
- SET_DEFAULT : 将外键字段设为默认值。只有当字段设置了default参数时,方可使用。
- DO_NOTHING : 什么也不做。
SET(): 设置为一个传递给SET()的值或者一个回调函数的返回值。注意大小写。
该参数用于限制外键所能关联的对象,只能用于Django的ModelForm(Django的表单模块)和admin后台,对其它场合无限制功能。其值可以是一个字典、Q对象或者一个返回字典或Q对象的函数调用,
staff_member = models.ForeignKey(
User,
on_delete=models.CASCADE,
limit_choices_to={'is_staff': True},
)
多对多(ManyToManyField)
对于多对多关系, 在 Django 中对于多对多关系的字段类的定义如下所示:
class ManyToManyField(to, **options)
我们一般会根据下面的示例来进行操作使用
from django.db import models
class Topping(models.Model):
# ...
pass
class Pizza(models.Model):
# ...
toppings = models.ManyToManyField(Topping)
一对一 (OneToOneField)
一对一关系类型的定义如下:
class OneToOneField(to, on_delete, parent_link=False, **options)
一对一关系模型多数用于当一个模型需要从别的模型扩展而来的情况。比如,Django自带auth模块的User用户表,如果你想在自己的项目里创建用户模型,又想方便的使用Django的auth中的一些功能,那么一个方案就是在你的用户模型里,使用一对一关系,添加一个与auth模块User模型的关联字段。
from django.conf import settings
from django.db import models
# 两个字段都使用一对一关联到了Django内置的auth模块中的User模型
class MySpecialUser(models.Model):
user = models.OneToOneField(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
)
supervisor = models.OneToOneField(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
related_name='supervisor_of',
)
这样下来,你的User模型将拥有下面的属性:
>>> user = User.objects.get(pk=1)
>>> hasattr(user, 'myspecialuser')
True
>>> hasattr(user, 'supervisor_of')
True
OneToOneField一对一关系拥有和多对一外键关系一样的额外可选参数,只是多了一个不常用的parent_link参数。
多对多中间表介绍
对于 ManyToMany 关系, Django 采用的是第三张中间表的方式。通过这第三张表,来关联ManyToMany的双方。下面我们根据一个具体的例子,详细解说中间表的使用。
默认中间表
首先我们来看一下默认的中间表
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self):
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person)
def __str__(self):
return self.name
在上面的模型中, 通过 members 字段, 以 ManyToMany 方式与 Person 模型建立了关系。到数据库查看一下实际内容, 可以看到 Django为我们创建了三张数据表,其中的 polls 是应用名。

serializers
Django 的序列化工具, 可以让我们将 Django 的 Model 翻译为其他格式的数据, 用于进行 数据交换/传输
序列化 : Djangon 数据库 --> Django 的模型 --> JSON/XML等文本格式 反序列化 : JSON/XML等文本格式 --> Django 的模型 --> Djangon 数据库
Django 默认提供了一个序列化的工具 serializers, 使用他也很简单, 我们只需要按照下面的方式进行使用
from django.core import serializers
data = serializers.serialize("xml", Person.objects.all())
通过调用 serializers.serialize() 函数, 并传递对应的参数: 序列化的数据格式和数据对象(数据通常是ORM模型的QuerySet,一个可迭代的对象)
- 序列化指定字段
- 序列化继承模型
如果你不想序列化模型对象所有字段的内容,只想序列化某些指定的字段,可以使用fields 参数
from django.core import serializers
data = serializers.serialize('xml', SomeModel.objects.all(), fields=('name','size'))
这样,只有name和size字段会被序列化。但是,有一个例外,模型的主键pk被隐式输出了,虽然它并不包含在fields参数中。
对于一个模型继承, 其在处理方面也存在一些不同之处
class Place(models.Model):
name = models.CharField(max_length=50)
class Restaurant(Place):
serves_hot_dogs = models.BooleanField(default=False)
如果只序列化 Restaurant 的模型数据, 序列化输出上的字段将只包含serves_hot_dogs属性。基类的name属性并不会一起序列化。
data = serializers.serialize('xml', Restaurant.objects.all())
为了完全序列化Restaurant实例,还需要将Place模型序列化,如下所示:
all_objects = [*Restaurant.objects.all(), *Place.objects.all()]
data = serializers.serialize('xml', all_objects)
当进行反序列化操作时我们只需要调用 serializers.deserialize() 就可以返回一个迭代器, 之后进行输出就可以了
for obj in serializers.deserialize("xml", data):
print(str(i))
其中的data是我们以前序列化后生成的数据(一个字符串或者数据流)。deserialize() 方法返回的是一个迭代器,通过for循环,拿到它内部的每个元素。
- 验证数据合法性
- 处理关联字段
- 局部更新
- 批量创建
- 批量更新
- 更新混杂创建